Reinforcement Learning for Engineers in a Hurry
Simple and practical RL leveraging Keras and OpenAI Gym




What is Reinforcement Learning?
Reinforcement Learning (RL) in the context of Machine Learning (ML) is one of the three fundamental ML paradigms.
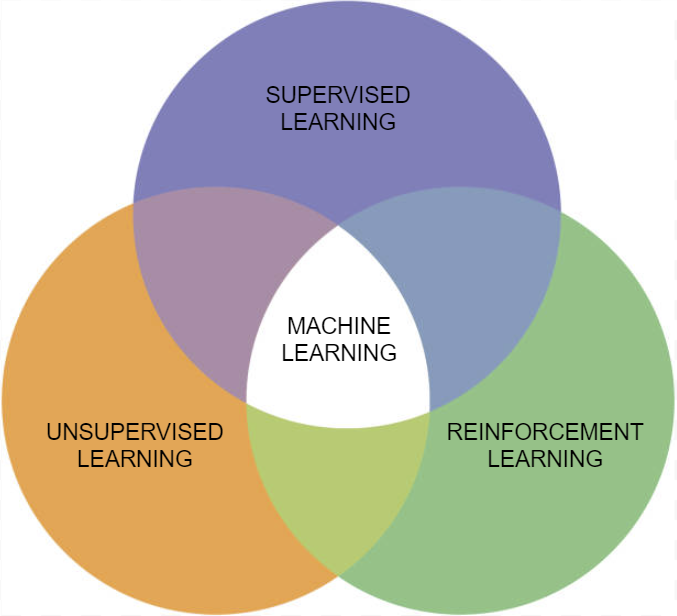
To properly answer this question, we first need to dive into the different aspects of RL.
Herein, we will use certain terminology to discuss the nature of RL. It is crucial to understand their meanings and how they distinguish RL from the other branches of ML. To get things started, we will present the notion of an agent existing in an environment.
An environment in the relevant context refers to a space - not necessarily a physical one - that exists and can be interacted with. Interactions with such an environment are called actions and should produce some sort of response that can be percieved by anything existing in that environment.
An agent exists in an environment and is able to percieve it, meaning that any response that the environment produces can be experienced by the agent. More specifically, an intelligent agent (IA) is one who takes non-random actions based on feedback from an environment. This feedback comes in the form of two notions, state and reward, which we will discuss more later. An IA takes said actions in order to reach some desirable end result. They may exhibit learning by adjusting their actions over time, or memory by using past experiences in an environment to adjust their current actions.
Putting these concepts together, RL involves an agent learning to take actions in an environment to reach some goal.
Making a Move
For the purpose of RL, it is necessary to have actions performed in a controlled and measurable manner so that we may use information produced by the environment for the benefit of learning. This is where our step function comes into play. A step function can be thought of as the process of taking an action, and recieving a response. It is best summarized in a diagram.
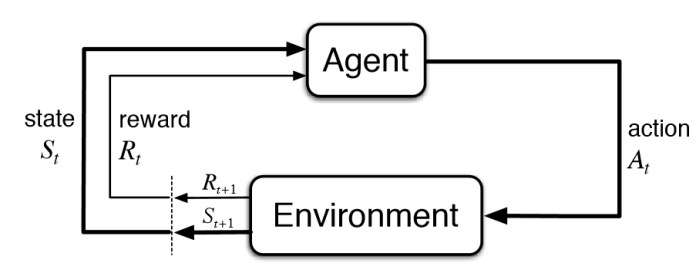
We see the aforementioned terms state and reward appearing in this flowchart. The state of the environment embodies some variable that describes the environment and changes over time. For example, humidity may be a state variable of the atmosphere. The reward is some feedback from the environment that characterizes the action taken by the agent. A desirable action outcome recieves a positive reward, while an undesireable outcome recieves a negative reward.
An agent chooses to take an action A on the environment at time t based on the current state S at that same time t. The current action A applied on the environment results in a new state produced at time t+1. As we 'take a step,' The new state becomes the current, producing a certain action. The cycle repeats, each being called a step. This results in a continuous feedback loop that allows the agent to exist meaningfully.
Decisions, Decisions
The pertinent question still remains, how does an IA make decisions, or learn to do so? Noteably in the previous section, we had little to say about the reward aspect of the flowchart. This reward is what teaches our IA to make certain decisions.
The 'brain' of the IA is the policy network. In essence, this is a mathematical function that takes a set of inputs and maps them to an output space. This function has parameters that can be changed to produce different outputs for a given input set. We can exploit this relationship if we are able to determine how to tune these parameters such that the mapping function always leads our IA to the best output based on its inputs. This is the concept of learning.
More specifically, in RL an IA learns to tune these parameters so that it always makes the best choice for a given environment state. The notion of 'best' is where our reward comes in. If an IA recieves a positive reward for an action performed due to an input state, we tune the policy network's parameters such that the IA is a bit more likely to produce the same action the next time that state comes around. If an IA recieves a negative reward (penalty), we do the opposite and tune so that it is less likely to repeat this behaviour.
The 'tuning' process is a vastly complex topic that need not be explained here to grasp the idea of RL. It suffices to know why this tuning happens and how it affects the IA's behaviour.
The Brain
For the purpose of this tutorial, we will use a Neural Network (NN) as the policy network for our IA.
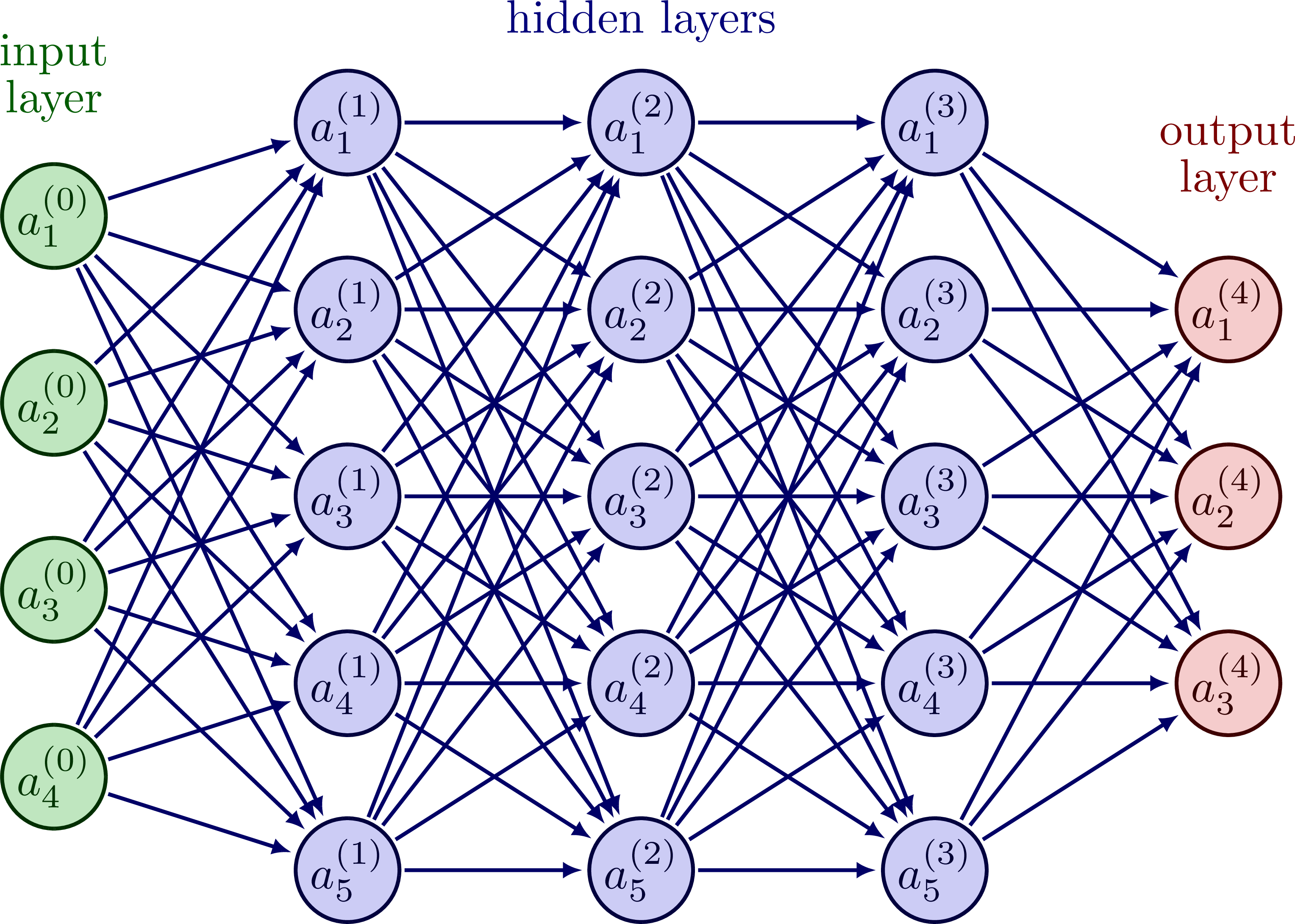
Neural networks reflect the way that biological brains are designed (in a very simplified manner, that is). Once again, NNs are realtively complex and will not be explained here, but it suffices to know that they fit the role of a policy network. The NN has tunable parameters (weights, biases), an input layer (for our state) and an output layer (for our action). The weights and biases will be varied according to the reward recieved during learning.
Putting the Pieces Together
All in all, we end up with a diagram that looks like the following.
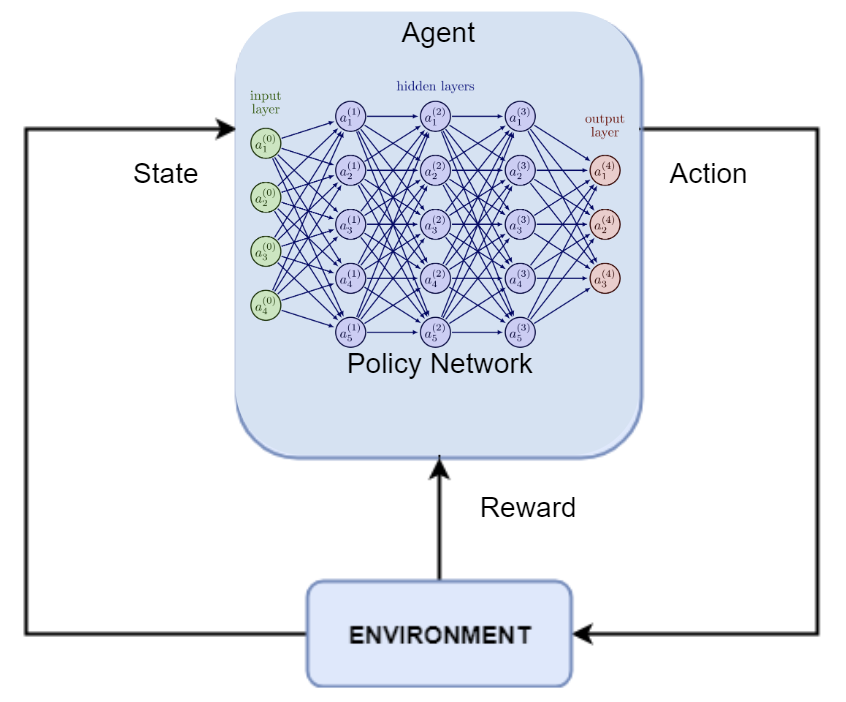
The NN takes actions based on the state. When learning, the reward updates the parameters of the NN.
Something to note is that when the agent is not learning, the rewards are out the picture. Rewards are only present when learning, and otherwise, our agent is only able to see the state of the environment.
We will be working in Python, using Keras/Tensorflow as our backbone as well as a reinforcement learning API, Keras-RL. Additionally, to simplify the creation of an environment we will be leveraging OpenAI Gym 1 which presents many simple environments with states, steps, actions, rewards and such already integrated.
#!pip install numpy
#!pip install gym
#!pip install pygame
#!pip install tensorflow==2.5.0
#!pip install keras
#!pip install keras-rl2
#!pip install nnv
We make the necessary imports to get started with the design of our environment.
import gym
import random
import warnings
Next, we can start setting up our environment as follows.
env = gym.make("CartPole-v1")
For the purpose of this demonstration, I have chosen a simple game as the environment. The CartPole game runs on PyGame, and has the user attempt to balance a leaning pole on a moving cart.
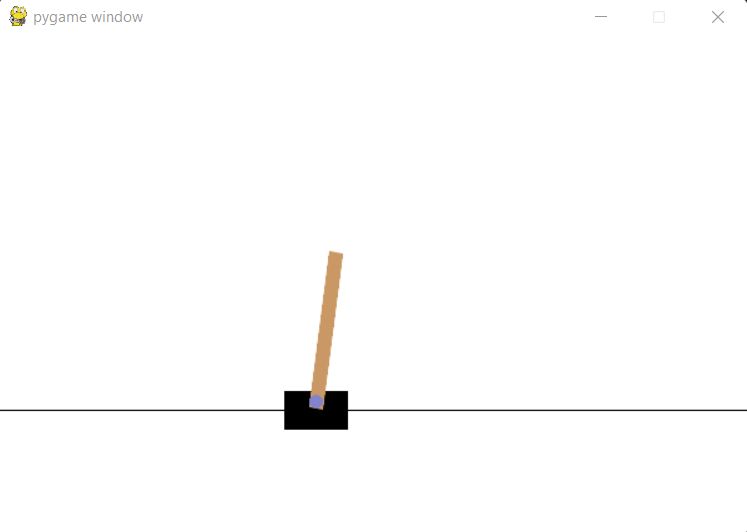
Let's learn a bit about our environment. What are the sizes of our state and action spaces?
states = env.observation_space.shape[0]
actions = env.action_space.n
print(states,actions)
As we can see, our environment has 4 states and 2 possible actions. A bit of digging into the OpenAI Gym documentation and we are able to figure out what these actually are.

The 4 states are the cart position and velocity, and pole angle and angular velocity. We can see the various boundaries for each of these states in the above tables. For context, the cart position is calculated from the origin and its velocity is the the difference in its position per step. Similarly, the pole angle is measured from the normal to the cart axis and the angular velocity is the change in this angle per step. These 4 states will serve as the input into our policy network.
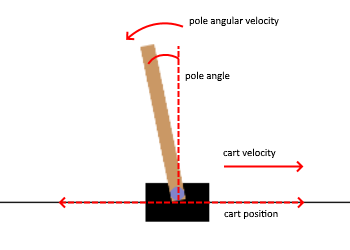
Now is probably a good time to mention that a step does not necessarily have to coincide with a unit of real time. As such, velocity in the above states does not involve change per unit time but rather change per step.
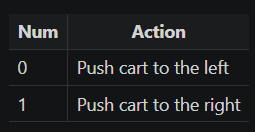
The 2 actions that we can take involve moving the cart in either the positive or negative x direction ([1,0] respectively). These represent the output of our policy network.
Looking into the documentation, the game is bounded by certain rules. We recieve a +1 reward (score) for each step in which the pole is still upright. Upright implies that the pole is within the angle range [-0.2095,0.2095]. The game terminates at a max score of 500, when the pole is no longer upright, or when the cart position exits the limits [-2.4, 2.4] - whichever condition is reached first.
Now, we will attempt to test our environment with a random agent - one which does not have a policy network and makes decisions randomly.
def RandomAgentTest(environment,episodes):
total = 0 #Running summation of the score in each game run
for episode in range(1, episodes+1): #Run game 'episode' number of times
state = environment.reset() #reset game environment to the base state
done = False #variable holds boolean corresponding to whether game episode is complete or not
score = 0 #current episode score, resets to 0
while not done:
environment.render() #start our environment
action = random.choice([0,1]) #Choose a random action from action space. 1 -> move right, 0 -> move left
n_state, reward, done, info = environment.step(action) #Take random action
score+=reward #Add reward to cumulative score
print('Episode:{} Score:{}'.format(episode, score))
total = total + score
print('---------------------')
print('Mean score over',episodes,'episodes --> ',total/episodes)
RandomAgentTest(env,10)
As a frame of reference, this game has a maximum score of 500. As we can see, random actions give a very poor score.
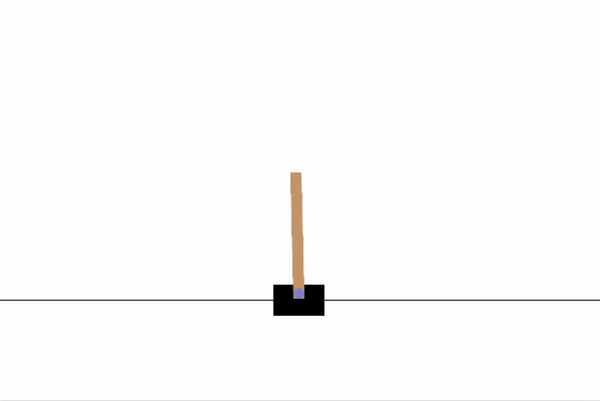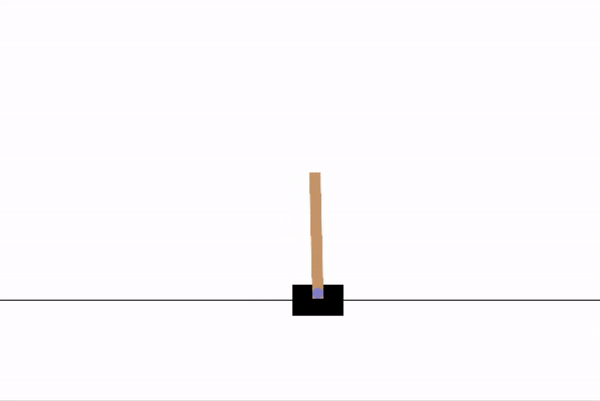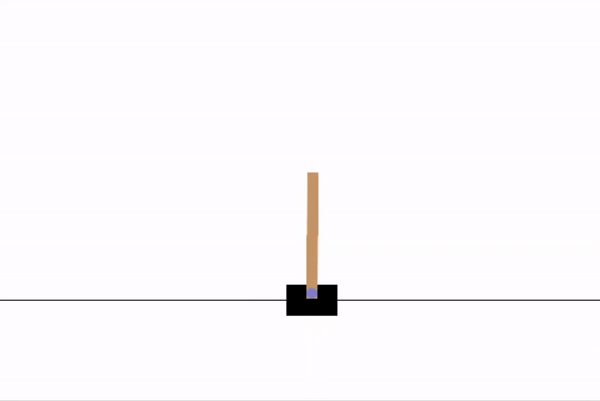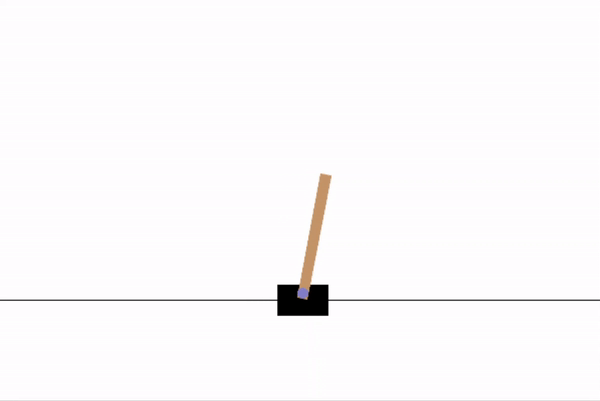
Now, we will design a policy network for our agent to give it the ability to learn.
First, we need to import the necessary resources.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import SGD
from rl.agents import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
Our RL model need not be too complex, as the game that is being tackled is relatively simple. We need the input of the network to accept our 4 states, and we need an output of 2 actions. The action with the higher activation at the network's output is the action that the agent will perform.
For the hidden (inner) layers of the NN, we will have two dense (fully connected) layers. Each layer will have 12 neurons, with ReLU activation between layers (to prevent the layers from collapsing into a linear function).
model = Sequential()
model.add(Flatten(input_shape=(1,states))) #'states' variable holds the number of states of the environment (4 inputs)
model.add(Dense(12,activation='relu')) #dense -> fully connected layer, relu activation between layers. 12 neurons.
model.add(Dense(12, activation='relu'))
model.add(Dense(actions, activation='linear')) #'actions' variable holds the number of actions of the environment (2 outputs)
model.summary()
For a visual representation of the above NN:
from nnv import NNV
layers = [
{"title":"input\n(states)", "units": states, "color": "darkBlue","edges_color":"red"},
{"title":"hidden 1\n(relu)", "units": 12, "edges_color":"black"},
{"title":"hidden 2\n(relu)", "units": 12, "edges_color":"red"},
{"title":"output\n(actions)", "units": actions,"color": "darkBlue"}, ]
NNV(layers).render()

Now that we are at the training stage, we will expain some key topics necessary to having a general understanding of the process.
Replay memory is essentially a catalogue of past states and actions kept when training our agent. 2 Keras-RL provides a convenient class for storing this information, which can be used as follows.
memory = SequentialMemory(limit=50000, window_length=1)
The 'limit' hyperparameter specifies the size of memory made available during training. When we surpass 50000 experiences, the oldest will be replaced by the newest.
This begs the question - why do we need memory when training?
When we train our IA, it easy to build sequential correlation between actions and states. In simpler terms, if we train our agent on states as they come with time (sequentially), we run the risk of teaching our agent to perform actions soleley based on time, rather than information recieved from the environment. As such, we sample batches of experiences from our memory at random when training our agent as to break this correlation. 2
A great analogy here would be a comparison between 2 hypothetical students taking a multiple choice math exam. Student A gets hold of the answer key, and decides to remember the answer to every question based on its number in order. Student B decides to study the content, and learn how to answer each question based on what is asked. Student A here reflects training our agent without memory, relying solely on the sequential order of the questions to know the corresponding answer. Student B understands what each question presents, and represents training with memory.
Policy in Keras-RL defines the strategy we use to train our NN. We will be using a simple ε-greedy policy which seeks to balance exploration and exploitation. 2
policy = EpsGreedyQPolicy(eps=0.3)
The 'eps' hyperparameter controls the probability of exploration, and therefore eps=0.3 implies a 30% probability of exploration.
Exploration involves the agent taking random actions in its environment, allowing it to find new 'paths' of actions that it can take to optimize the reward.
Exploitation involves the agent taking actions with the highest expected reward, allowing it to follow 'paths' of actions that yielded greater reward in previous episodes.
We will now put these concepts into play during our training.
agent = DQNAgent(model=model, memory=memory, policy=policy ,nb_actions=actions, nb_steps_warmup=1000)
First, we must create our agent object with references to our model, memory, and policy as seen above. We can define the number of actions that our agent can take through the 'nb_actions' parameter. Furthermore, the parameter 'nb_steps_warmup' allows us to define how many steps our agent should take before we begin to sample from memory for training.
In terms of our optimizer, we will be using Stochastic Gradient Descent (SGD). SGD is the agorithm responsible for adjusting the weights inside of our neural network, details of which we will not go into. Learning Rate (learning_rate) is a hyperparameter that influences the optimization of our NN weights. For a performance metric, we will use mean squared error (mse).
agent.compile(SGD(learning_rate=1e-3), metrics=['mse'])
The next step involves the training of our agent. We will call our .fit() method, which initiates this training. To this method we pass our environment, and give a limit to the number of steps for which we will train. Additionally, we set visualize to False so that our environment is not visible while training, as this would slow down the process.
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", category=UserWarning) #Suppressing Deprecation & User Warnings
agent.fit(env, nb_steps=30000, visualize=False, verbose=1)
Now that we have our trained agent, we can test our agent's performance inside of the environment and compare it to our random agent at the beginning of this tutorial.
n_test_episodes = 20
scores = agent.test(env, nb_episodes=n_test_episodes, visualize=0)
print('---------------------------------------')
print('Mean score over',n_test_episodes,'is ---> ', np.mean(scores.history['episode_reward']))
RandomAgentTest(env,20)
If we observe the above output cells, we can see that our trained agent averaged a score of 207.1 over 20 episodes, while our random agent averaged 26.4 - a huge difference!
We can see how our IA performs on a single run of the game below.
agent.test(env, nb_episodes=1, visualize=1)
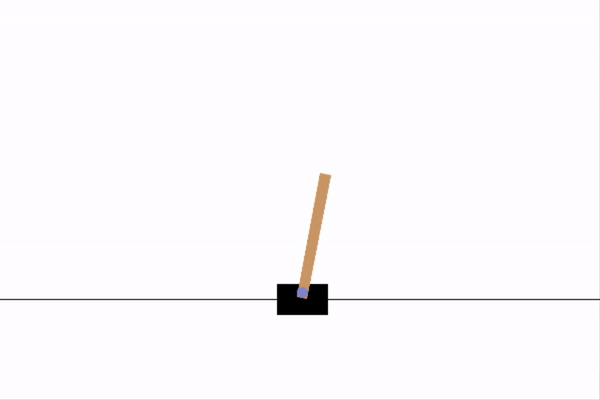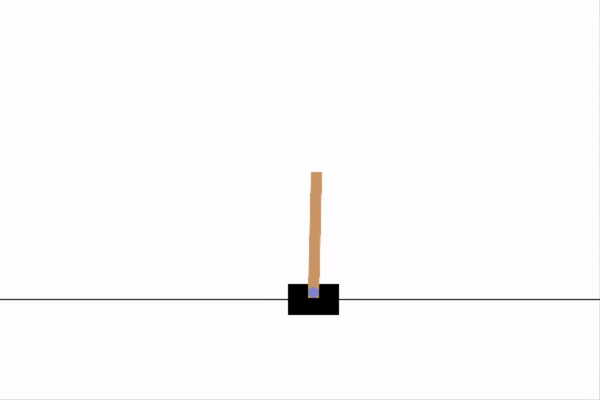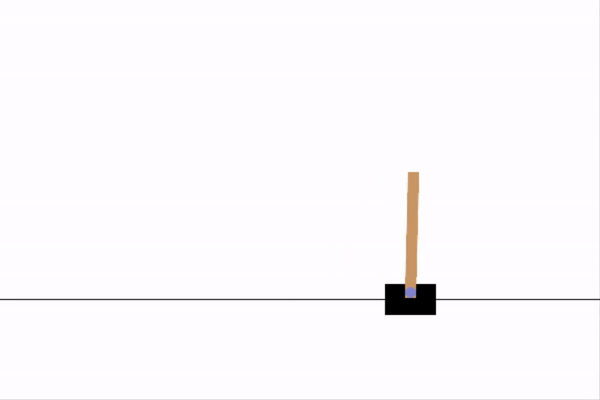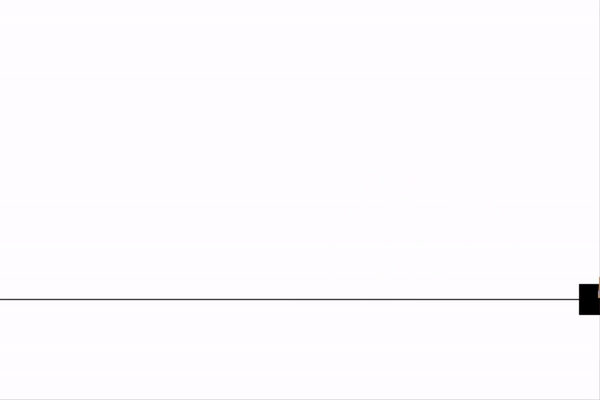
Note the ability of the agent to keep the pole balanced for a significantly longer period of time when contrasted to the random agent. This difference reflects the fact that we now have an agent with some hint of useful decision making.
It is with some caution that we can say that our trained agent is now 'smart enough' to play this game.
As we can infer, RL has numerous applications that extend from such a simplistic environment and can find usefulness in a large scope of fields. It is a field with diverse reach that finds a place for itself in a modern world concerned with automation. Simple environments like the one presented here can serve as an analogue to more real-world problems. Having given this introduction, I implore the reader to further their knowledge into Reinforcement Learning.
Hopefully this read has made you wonder how you can apply RL to other tasks similar to the one presented here. A great stepping stone would be to look into the OpenAI Gym Documentation and explore the environemnets available its users, which range from Atari game recreations to simple 3D locomotion simulations. Try your hand at creating an agent to traverse these environments and along the way explore the various tweaks that can be applied during training to maximize your score!