Why SQL?
Displaying the real-word utility of SQL and Relational Databases
- Overview
- Introduction
- SQLite Background and Review
- Using SQLite
- Motivating Example
- Creating a Relational Database Model using SQLite
- Creating Transactions
- Conclusion
- References
- Public Github Repository
Overview
In this blog post, I intend to show the utility of SQL database applications by displaying a hypothetical example of where an SQL Database is used in a retail setting. Through doing this, I intend to “make the game worth playing”, referencing David Perkins’ 2008 book Making Learning Whole: How Seven Principles of Teaching Can Transform Education, by showing the capabilities of SQL and how it outperforms that of the comma separated value. Although the abilities of SQL go far beyond the capability of this program, I intend to open up the reader to a real world application of SQL, extending the content learned in the course ENDG 311.
Introduction
In my first few years of Python learning, the comma separated value file reigned supreme as a means of storing and accessing data to be manipulated and visualized. In my second year digital engineering course ENDG 311, I was introduced to Structured Query Language, or SQL, as an alternative means of accessing data from relational databases. More specifically, I was introduced to the python compatible, serverless application SQLite. In this introduction, I learned the basics behind SQLite and used this to create small scale databases to store and manipulate data.
Although I was introduced to a new way of storing and accessing data, the small scale nature of the projects made me wonder what was ever wrong with the simplicity and ease of using CSVs. It was this confusion that led me to ask, “Why in the world would I use SQL?”, and as such warranted further digging. Aligning with Professor David Perkins’ seven principles of learning seen in the 2008 book, Making Learning Whole: How Seven Principles of Teaching Can Transform Education, I plan to “make the game worth playing” by diving deeper into the real world applications and usefulness of Structured Query Language along with concepts of data visualization learned in digital engineering courses, looking to answer the overarching question, “Why SQL?”
Before taking this dive further into SQL and SQLite, let us first review some basic SQL queries and background. For some, this may be completely new, and for others this may be a brief refresher, all in all this part looks to catch you up to speed with the SQL taught in ENDG 311.
SQLite Background and Review
SQL is a way in which we can access data stored in relational databases. By relational database, I am referring to a network of numerous structured tables that are related to one another. Unlike piling data into one immensely overcrowded excel spreadsheet or csv, relational databases serve to organize data in tables, and then draw connections between these tables to create a system made up of numerous smaller entities making it easier to organize data. With this system of tables, each made up of predefined columns, each row serves as an entry of data. In the relational database structure, you can choose to specify whether or not columns must have unique entries or not. One thing most (not all tables) have in a relational database is called a primary key, which serves as the unique attribute for each row of the table. To better understand this concept it is best to use an example.
A great example I’ve found helpful in explaining this topic is the relational database structure of a library. We can start with a table of books, with a Unique Book ID (Primary Key), Title, Year of Publish, and Author. If we wanted to have more information on the author it wouldn’t make sense to have it repeated over and over again as there can be one author with many books. As such we can create another table for Authors, with a unique author ID, their first name, last name, date of birth, hometown, genre, etc. With this table instead we can replace the Author in the books table with the Author ID creating a one to many relationship between the two tables and allowing for all the information to be accessible without wasting millions of lines repeating information. This is essentially what is done with a relational database structure; making data more seamlessly arranged for better storage and access.
To access and manipulate data stored in these databases, we use SQL queries, which are statements that utilize keywords to perform certain operations. In a very general way, these operations are CRUD operations seen in the table below:
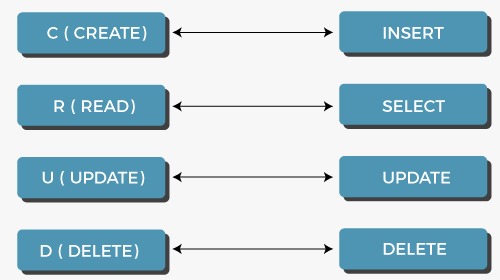
In SQL there are numerous keywords reserved to perform specific operations on data set forth in a relational database. For reference, a list of a few keywords and example uses has been attached below:
* CREATE - Creates a Table with outlined column titles
i.e CREATE TABLE table_name(column_1 primary key, column_2 type)
* SELECT - Used to access certain columns from a table
i.e SELECT * FROM table_name
* WHERE - Used to find data based on conditional statements i.e WHERE value > 6
i.e SELECT * FROM table_name WHERE id = 2
* INSERT INTO - Adding rows to a table
i.e INSERT INTO table-name (the values corresponding to each column)
* UPDATE - Used to update an entry
i.e UPDATE table-name SET column-name = value1 WHERE column-name = value2
* DELETE - Used to delete an entry
i.e DELETE FROM table-name WHERE column-name = value
* DROP - Used to delete a table
i.e DROP TABLE table-name
Much like Python, SQLite also has certain data types that can be specified in queries when creating tables. Most commonly in this post I will be dealing with the data types INTEGER (much like that of integers in Python), REAL (much like that of floats in Python), TEXT (much like that of strings in Python), and lastly NULL values (much like the None keyword in Python).
Using SQLite
For many, SQLite may come prepackaged with Python, however for some like myself, this is not the case. To test this out feel free to open up a command prompt in your IDE and type into your terminal “sqlite3”. The resulting output should look something like the following:

If this isn’t the case, then head over to SQLite’s downloads section. From there find the respective precompiled binaries for your respective operating system, and download the associated files. For windows users like myself, the following item should be downloaded:
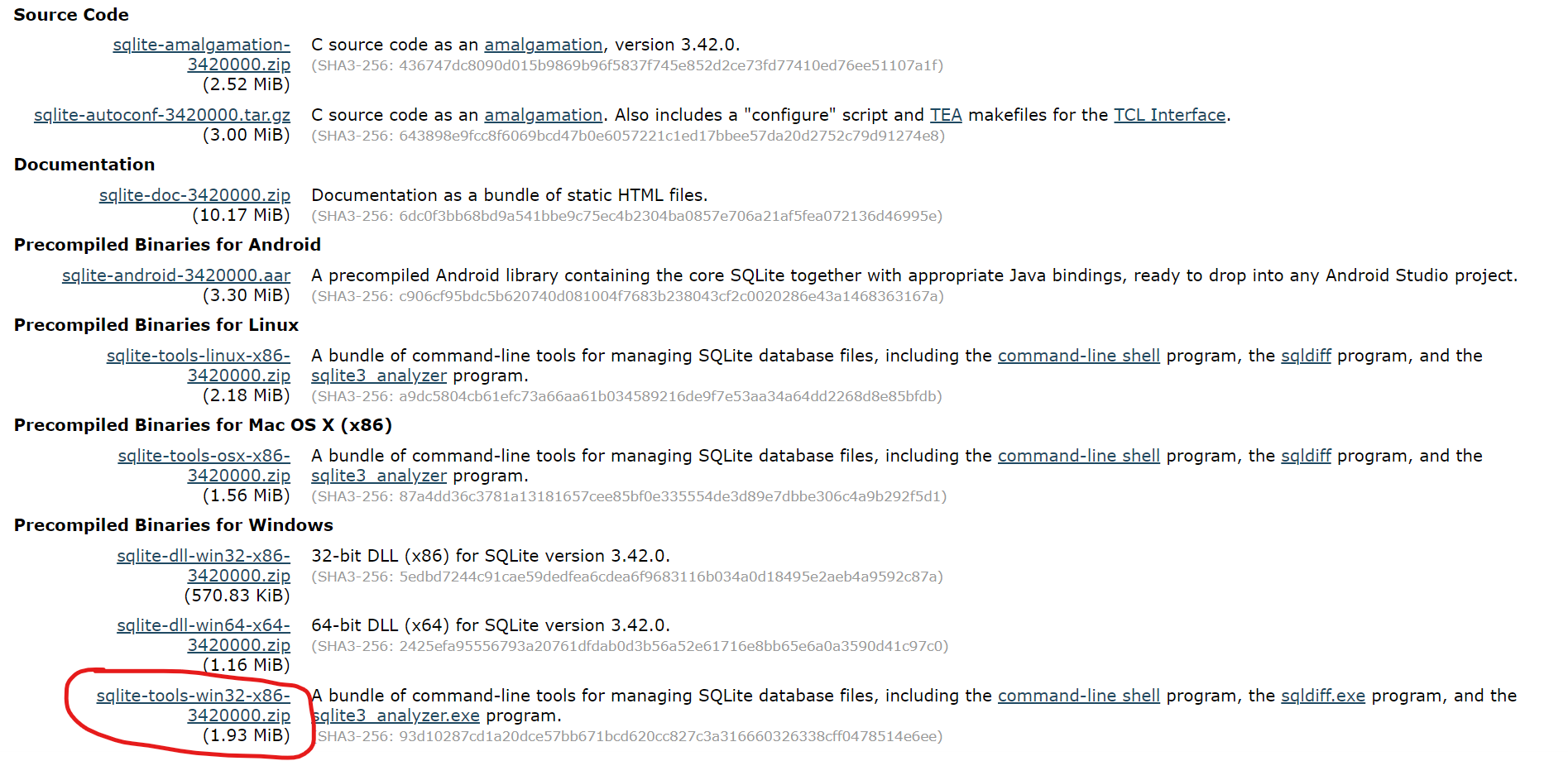
For any operating system ensure the files you download are described as “A bundle of command-line tools for managing SQLite database files…”. With these binaries installed, place them into a folder; for reference I created a folder named SQLite, and ensure that you add them to the Path environment variable for your system. To do this on windows, type in the environment into the Start menu and click on the control panel option “Edit the system environment variables”. From here follow the steps outlined below:
1) Click on Environment Variables:
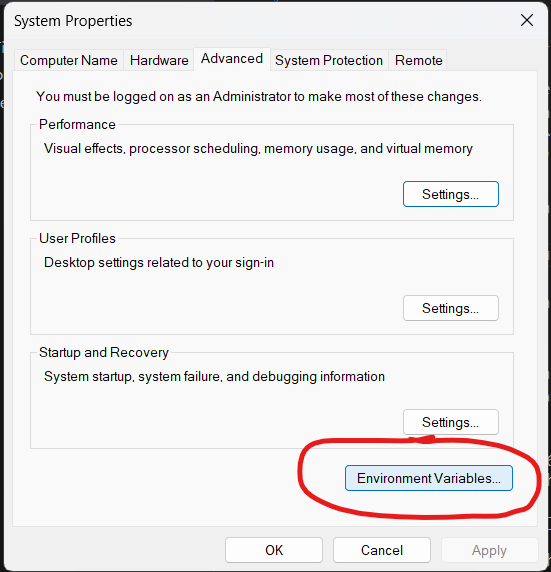
2) Under system variables double click the variable named Path
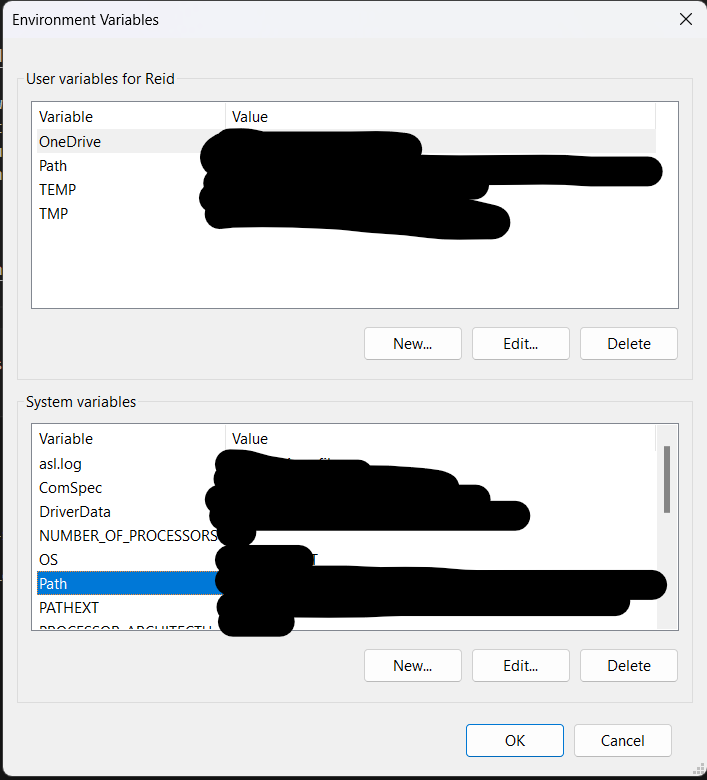
3) Copy the entire file path to the folder containing your downloaded SQLite files
4) Click on New and paste your file path where prompted
With these four steps followed you should now be able to use SQLite in the cmd terminal by typing sqlite3. To open the database you want to immediately you can type FILE_NAME.sqlite instead of just sqlite3. Or you can execute .open FILE_NAME.sqlite after opening the sqlite3 terminal. Either way works, so feel free to choose one.
To exit the SQLite terminal type in .exit. SQLite terminals have many other “dot” commands to perform certain functions all listed in the SQLite documentation. A quick note is that dot commands can not be used in python script and are restricted to use in the terminal. The sqlite3 terminal serves as a useful way to query a database that was altered in a python file to see the outcome, hence I recommend trying out some queries in the terminal. NOTE: all queries in the terminal must be followed by a semi colon to be executed. This practice of ending queries with a semi colon can be used for queries in python scripts but is not required.
Now with SQLite installed and ready to go, we can execute SQL queries within a python document by importing sqlite3 and setting up two things; a connection and a cursor. The connection serves to connect the python document to the database and the cursor allows us to be able to execute SQL queries on said database. An example of a simple interaction to open a new sqlite database file named introduction.sqlite and create a table called students is attached in the python document sqlite-intro.py.
With this simple one table database I encourage you to practice getting comfortable with some of the basic SQL queries listed earlier and even try branching out to use other keywords such as the conditionals LIKE, AND, OR, NOT, or even try ordering the output using the query ORDER BY, or use the built in functions like max(), min(), avg(), sum(), and count() to perform computations on numeric data. In this introduction file, I have included queries to show the correct syntax for many of the common queries I’ll be using.
With this intro into SQL using only a single table database I couldn’t help but think, “Why not just use a CSV? What is the point of SQL? Why SQL?”. To answer this question let’s move forward into a motivating example relevant to a real world system.
Motivating Example
For this motivating example, I looked to create a scenario around a hobby of mine; bikes. More specifically around the business logic of a bike shop. In this I not only look to look deeper into SQL but also to “make the game worth playing” by looking into an actual real world scenario. Let’s say you are the store manager of the Bike Shop and need a system to process transactions and record transactions with customers and track sales metrics. If we were to generate a mock of what this table would look like using the code in motivating-example-large-table-generator.py, it would look something like the following:
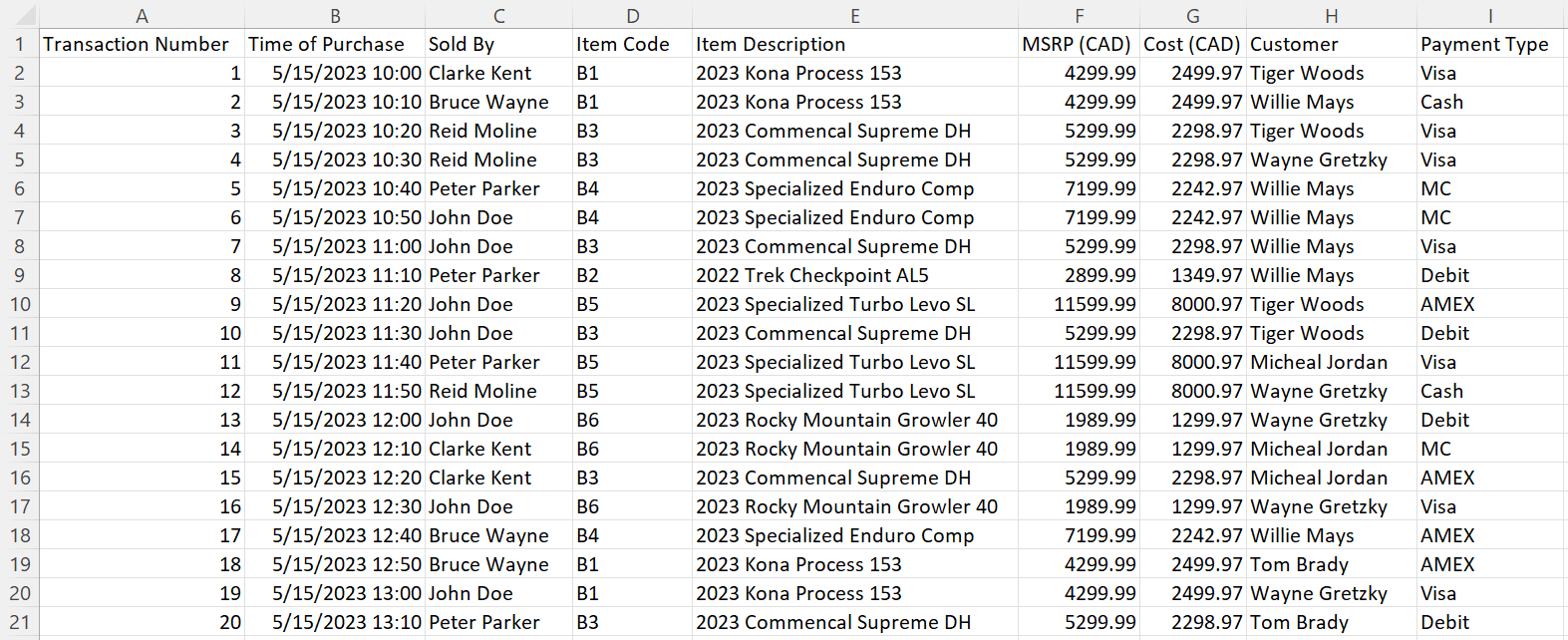
With this very over simplified table of one item transactions, a flaw begins to arise by changing the constant NUM_SALES to a larger number to mimic a busy sales day. In doing this, a simple 9 column table becomes super long and as such becomes more difficult to sift through for data. Furthermore, this table only considers simple one item transactions of a business; not taking into account transactions with more than one item. On top of that, there is way more information we can include about products, employees, and customers that if added would make this table huge! If we were to continue to add all of this to one table and format it as a CSV, it would be a horrendously large and jumbled up array of data. This is where a relational database structure can help.
Creating a Relational Database Model using SQLite
NOTE: In the creation of this database I used foreign key constraints between tables, something that needs to be enabled in sqlite. When I open bikeshop.sqlite in the terminal this is done by executing the query, “PRAGMA foreign_keys = ON;”. In a python script this is the first line executed by the cursor to ensure that foreign key constraints, which I will cover later, are enabled. Furthermore, to revert to the initially created database I had generated, the file database_reset.py has to be run. As I go through the creation of each table I pretend as if the function to generate the other tables is not in the database_reset.py file, as they weren’t when I created the database table by table. By resetting the database, this clears all transactions recorded, and all issues to be reconciled.
Focussing only on the retail side of the business, we can begin to separate the portions of a transaction into four separate categories; the customers, the salespeople, the transactions, and the products. Although all four of these things are separate entities, they all relate to each other in one way or another. In formatting four separate tables for these items it can allow for us to organize a better system for storing retail records. On top of the four main tables, to stick to examples sparked by my interest I’m also including a table that will deal with the serialization of bikes, for like cars bikes are each equipped with a serial number from the manufacturer as a means of tracking ownership.
First off, we can start with creating a table for the people who run the show; the employees. For a basic record of all employees on staff we can generate a table including a unique employee ID, their first name, last name, work email, and phone number for contact purposes, as well as what department they belong to. An employer can use this table to find an employee’s contact info for shift trading, grab all emails to send an email to the entire staff, etc.. These queries and others have been included in the file employees.py. Running this file directly executes each query and shows what can be done with just this table to help the business. Furthermore, in this file I have defined the function create_filled_employees_table which can be called to create and fill a table of employees. Feel free to look through the code and see how this was done. Through calling this function in the file database_reset.py, and then running a query through the terminal, we get a table of the following form:
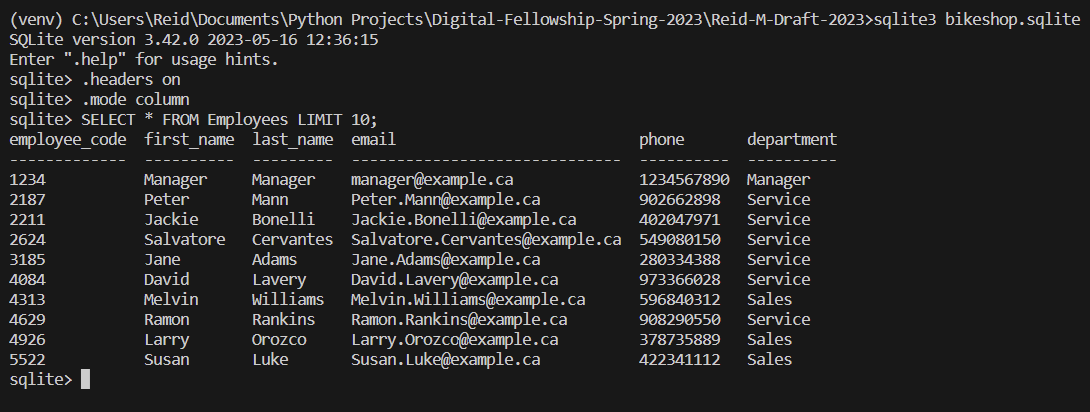
A quick note that I had created an employee account for a Manager with the employee ID 1234. This will serve useful later when I create transactions as I have a known login to use, and also allows us to have a guest customer profile. It may not make sense now, but keep reading and it’ll all come together.
I’ve also included some basic queries within the code in the file employees.py that outlines some potential ways this table can be useful to a business. Feel free to play around with this by adding more queries!
With our employee table generated, we can start with creating a table for the people who make having a business possible; the customers. With this we can include basic information that can help keep record of business, such as their first name, last name, email, and phone number. Given people can have the same first name and last name, as well as families can share the same email or land line phone number (yes some of us still have these), it would make sense to create a numeric customer ID to create different profiles. To track how well the employees that would be creating the customer IDs are, we can add the employee ID of who created the customer profile.
In creating this connection between customer and employee, we can create a foreign key constraint. This allows for the customers table column created_by to only contain employee codes that are actually in the employees table. This ensures proper information is relayed and someone can’t just go into the database and insert a random number into the created_by column.
If a customer does not want to have a profile added, they can opt out. This is one of the reasons why I created a Manager employee profile as I have made the code in the function create_filled_customers_table defined in customers.py so that a guest account with customer ID 0 can be made. This is so we can also track guest purchases.
Utilizing the function create_filled_customers_table defined in the file customers.py we can generate a filled table of randomly generated customers for our hypothetical business. By running the function create_filled_customers_table as seen in the file database_reset.py we can create a mock up table of customer profiles. Querying this table via the SQLite3 terminal we can see the following output:
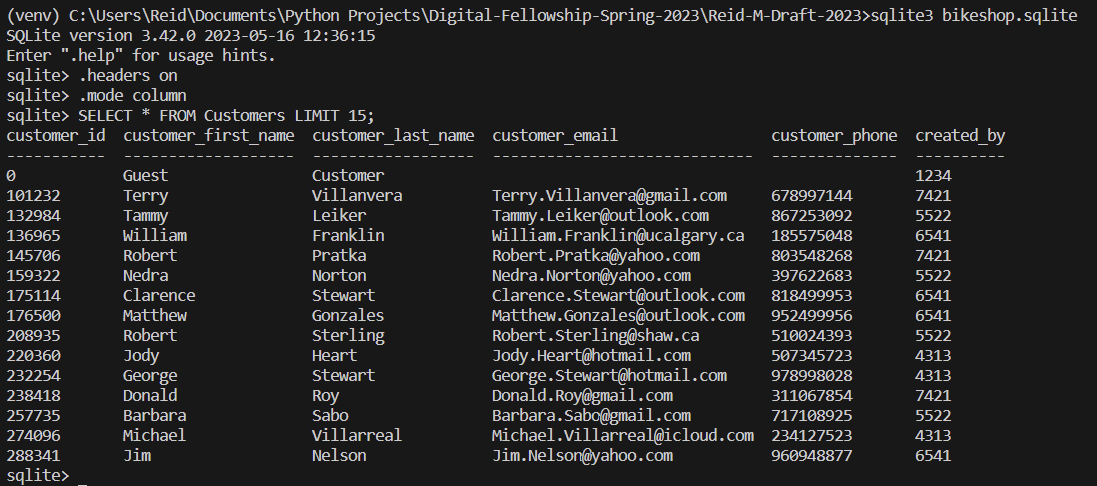
In the main code of customers.py (that runs only when we run the file customers.py directly), I included some queries to demonstrate a way employers can track how well their employees are capturing customers’ emails. This information would be able to be then taken back to the employee for performance reviews internally. Try adding more customers to the table via insert queries. Note that you do need to use a known and valid employee ID to insert a customer into the table. Luckily you can query this!
Moving on, we can generate a table for the products in store. Keeping it somewhat small compared to the amount of products a bike shop would carry, I’ve used my knowledge of bike brands, component specification levels, and sizes to create a table full of different bikes as well as accessories some would also see in a bike shop. In the file products.py, I’ve used this knowledge along with researched MSRP values from major bike brands websites and the assumed high sale margin of 45%, to generate the table seen below. For the products, I made it so that each product will have it’s own 12 digit universal product code (UPC), a description of the product, the quantity of the product on hand, the manufacturer’s suggested retail price (MSRP), the wholesale retailer’s cost of the unit, as well as whether or not the item is individually serialized. With this all considered, using the function create_filled_products_table defined in the file products.py, the generated table is of the following form:
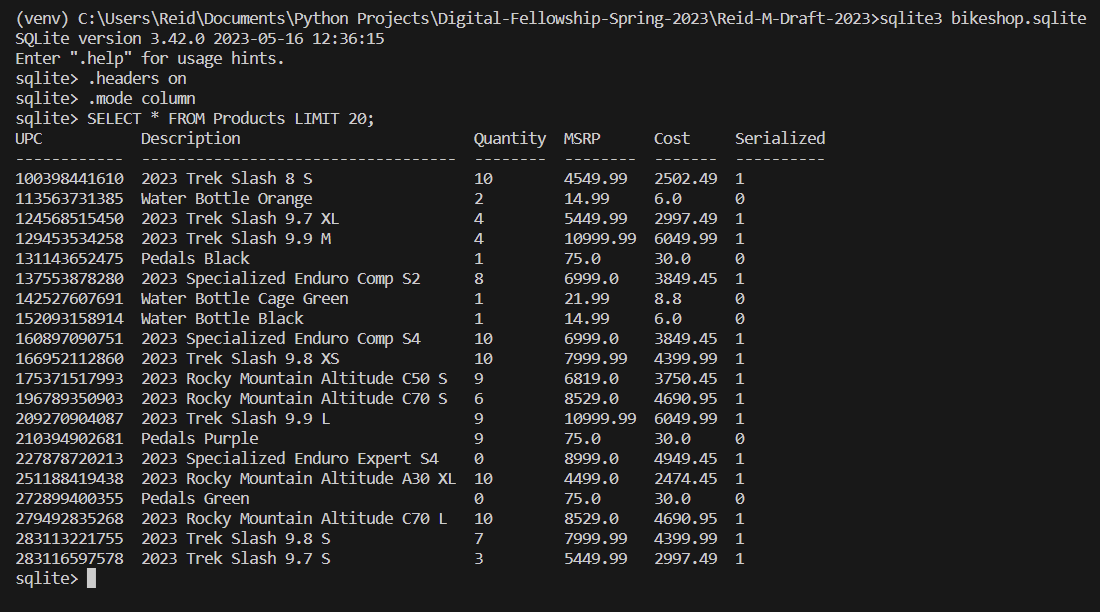
In the file products.py I have also included some queries to find out what items are out of stock. The business can use this to see what needs to be ordered soon. I have also added a few challenges to test your execution of queries. Feel free to give them a try!
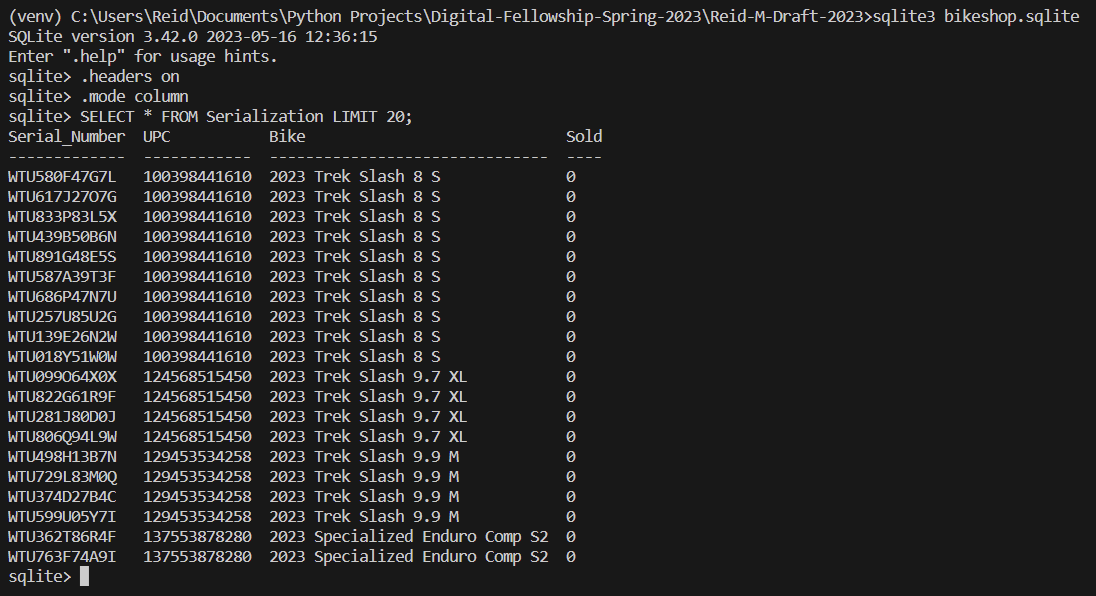
With a table of all products carried, staying true to the bike shop example, we must add in a table to record bike serialization. For the record of the business we can store these serial numbers within another table, along with the description of the bike, the UPC, and whether or not the bike is sold.
With the creation of this table, I included the UPC of the bike, however if incorrect data was input here that didn’t match a UPC in the products table the whole database would be flawed. As a way to stop this I introduced a foreign key constraint to the serialization table. By doing so I am ensuring the data put into the UPC column of the Serialization table contains a UPC that is actually in the Products database. This makes the database more robust against someone trying to enter in wrong information.
For the simplicity of creating this table, I have gone ahead and assumed all bike brands share a universal format for serialization, where the serial number is a 12 digit alphanumeric code starting with the letters WTU, a common start to serial numbers manufactured by Trek Bicycle Corporation. Using the code seen in the file serialization.py we can generate a table like the following:
With all of these tables created and some small connections created, it is now time to generate a table which links all these tables together, a table of transactions. With every transaction a business has it is good to track who makes the sale, who purchases the item, as well as recording what tender was used. To create this table as seen in the file transactions.py, I have created the table using the following query:
cursor.execute("""CREATE TABLE IF NOT EXISTS Transactions
(Transaction_Number INT NOT NULL,
customer_id INTEGER NOT NULL,
Item TEXT NOT NULL,
UPC INTEGER NOT NULL,
Item_Cost REAL,
Serial_Number TEXT DEFAULT NULL,
Salesperson_ID INT,
Payment_Type TEXT DEFAULT NULL,
Date TEXT,
FOREIGN KEY (customer_id) REFERENCES Customers (customer_id),
FOREIGN KEY (UPC) REFERENCES Products (UPC)
)""")
First and foremost notice this table doesn’t have a primary key. This is intended as it serves to compile foreign keys from other tables. In the creation of this table, I have outlined numerous foreign keys. Through this we get the link between all of our separate tables, as these constraints are what ensure the values under each of these columns must align with those already in the database.
With this retail transaction system, I am assuming the salesperson has the ability to scan barcodes for both the UPC of the item as well as the serial number of a bike if one is being purchased. These would tags the item in a real world retail setting. Furthermore, since we have an option to add the payment type for each item, I am assuming a third party device is being used to take payment and this is relayed manually by the user, a common practice I’ve seen in past jobs working retail.
With this table created using the function create_empty_transactions_table defined in transactions.py, We can move on to create actual transactions.
I have created a mock terminal based program that is meant to go through the process of a sale. First prompting for the salesperson’s ID, then finding the customer’s profile so it can track receipts, then going forward with “scanning” in the product. In a retail setting there would be a graphical user interface to perform this option, however for sake of keeping things simple, I have chosen to make this a terminal based application. It is entirely possible, using the SQLite backend to create a GUI using tkinter as taught in ENDG 311 further showing how we can combine concepts from the digital engineering course to create real world useful applications, making the game worth playing as David Perkins would put it.
Lastly, in the creation of this terminal based sale generator, I had realized that I needed a way to stop the sale from scanning through an item showing 0 in stock. This would create negative inventory and not be optimal in a real retail setting. To account for inventory issues found when scanning items and creating sales, i.e the computer showing no item in stock when the item is scanned, I have created a table called Reconcile which is generated in the function create_empty_reconcile_table defined in the file reconcoile.py. The purpose of this table is to record an inventory issue that arises when scanning, noting what transaction this occurred in, what the item UPC is, the date of the transaction, as well as the status of whether or not the issue has been resolved. This table can be used internally by management to see where issues in inventory are and allow them to fix them. This table is intended to track inventory issues of small priced item and allow them to still be sold to the customer. If a bike has an inventory issue then this warrants investigation and must be dealt with by someone immediately. This somewhat would mimic that of a real retail setting.
Creating Transactions
With the creation of these six interconnected tables we can start to create transaction and utilize the database. To emulate a real world setting, I have imagined that each time a person comes to the till with items a sale is started by running the file transactions.py, and thus using the terminal based process the employee can complete the sale.
Through querying the database created, we can ensure only proper employee credentials, customers, and items are used, allowing us to have proper records which are useful to the business. I encourage you to practice querying different tables of the database and find some employee IDs, customer IDs, product UPC, and serial numbers for bicycles, and try and go through the process of creating a sale. Then I encourage you to go back into the database and query the Transactions table to see the records pop up, and also check the updated quantities. For some help getting started I will show you the process.
Before I go through an example transaction let me state that I am using the exact database tables that are seen above. As such for these transactions I will be using potentially different customer and employee IDs as well as different quantity on hand if you reset the database using the file database_reset.py. In the end the system is the same, but I encourage you to query the database and find some customer IDs, employee IDs, UPCs (for Items with both 0 and non zero quantities), and serial numbers for respective items with matching UPCS. Feel free to enter in incorrect information as well, as I had designed routes to deal with incorrect information. Feel free to play around with this!
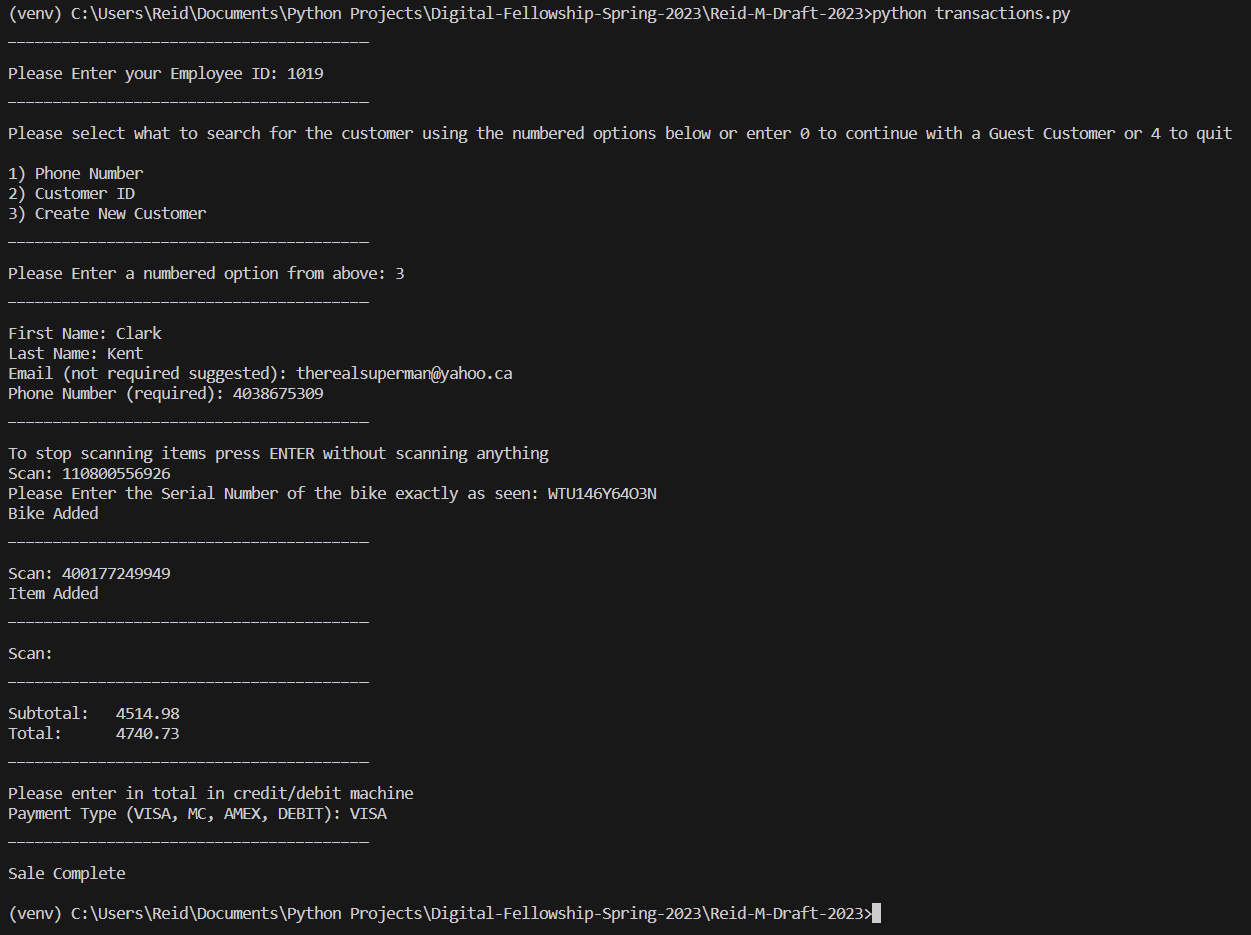
An example of a transaction being executed in the terminal is as follows:
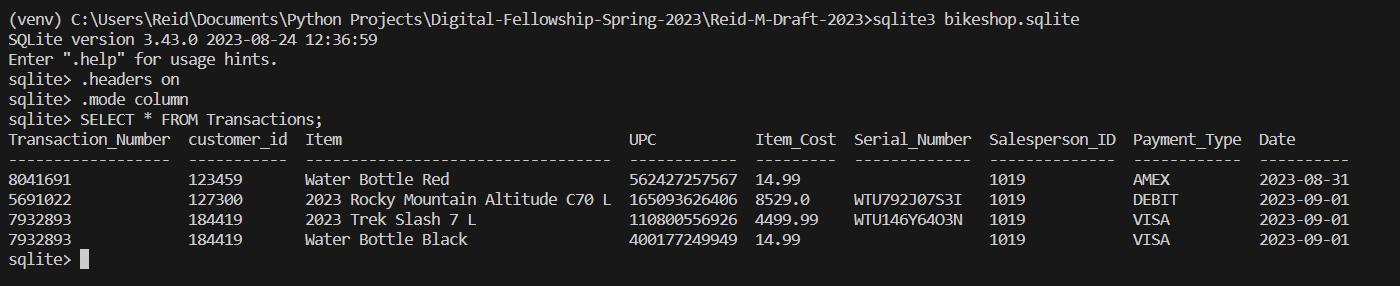
After running this script, we can enter the sqlite3 terminal and execute a few queries to check if this went through. First we can query the transaction table to see if it updated to show the transaction as seen below:
Notice how both the water bottle and bike sold to the customer show up under the same customer ID. But are we sure this is Clark Kent? We can query that like this:

And to check if the bike is registered as sold we can query the serialization table as follows:
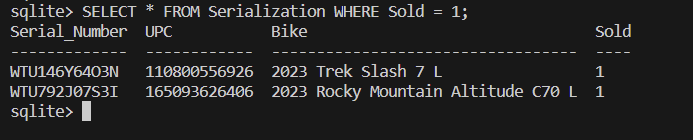
I encourage you to try this out and try scanning in items not in inventory and querying the reconcile table after to see how this is handled. All in all we have created a basic retail system to track transactions. If you’re really looking for a challenge try looking how to use queries using JOINS to combine tables and create unique output. This would be a great way to extend the funcitonality of this program.
Conclusion
In this blog post, I looked to venture further into SQL databases to prove the utility of them in the real world, and in the sense of an engineering student, showing why they are more useful for storing data then that of the CSV. In my investigation as to “Why SQL” I expanded on the material taught in ENDG 311 to produce an entry level retail system in which inventory and customer transactions can be tracked. Now there are clearly a lot more steps involved in creating a system that is useful to a real world application, but this gives a small taste into how useful SQL is in the real world. There is a lot more to explore with SQL from JOINS to more advanced queries and I encourage you to try and expand this system as a means of learning. In the words of David Perkins, I hope I “made the game worth playing” by showing how SQL can be applied to the real world.
References
- SQLite Documentation: https://www.sqlite.org/docs.html
- Education at Bat: Seven Principles for Educators: https://www.gse.harvard.edu/news/uk/09/01/education-bat-seven-principles-educators
- Crud Operations in SQL: https://www.javatpoint.com/crud-operations-in-sql
Public Github Repository
Below is where all associated code for this blog post is located: